
Credit Unions should own and know how to use their data. Period.
Legacy architectures, rarely update spreadsheets, unintuitive UIs, and siloed data storage leave employees, members, and leadership in a reactive state. Many vendors offer single solution dashboards to address specific needs, but often this further compounds the foundational problem: disparate data systems only provide a partial picture. But what if instead of just seeing the growth figures from a new membership campaign, you couldpredict your member attrition rate and the corresponding factors to avoid it. The real value of data is unlocked when data is both unified and accessible.
Fortunately, this is a case where the laggard nature (sorry team) of credit unions can actually be an advantage. Rather than wrangling your data to conform to outdated approaches, skip building landlines in a mobile world and go straight to a cloud-based data lake. In the past year, there has been an acceleration in the quality and accessibility of managed services from cloud providers like AWS that simplifies data lake formation and the use of pre-tuned machine learning models. This allows CUs to unify and securely store their data in its cheapest, raw form and enables advanced prediction to solve pressing challenges in real-time.
What the heck is a data lake?
Almost every CU has likely heard of or (often tragically) tried to implement a data warehouse. Data warehouses pair well with ETL, an extraction technique that formats data before putting it into storage. Much like a giant database where data is stored in a standard format, warehouses conform data to constraints to be queried more easily.
So how is a data lake different? An analogy might help here. There are two prototypical drawers in most kitchens: a utensil drawer where each type of utensil has its own special place and that catch-all-drawer where you throw everything else you need. The former is a data warehouse; the latter, a data lake.
A data lake can be thought of like a giant directory or file system. Data lakes pair well with ELT, an extraction technique that doesn’t alter the data before storing it. This simple-sounding difference has big implications. Anybody in the organization can store their data there, in any format, schema, or order.
But now you might ask, “Isn’t it easier to find a fork if all the forks are organized together?” Well, yes, it is easier to find a fork, but finding and counting forks is just scratching the surface of modern analytics. With today’s cheap and powerful computing, grouping things in whatever way you want is nearly instant. The data doesn’t need to be stored in a specific format, which opens the door to endless types of data analytics. Modern tools such as Spark/Hadoop can process any organizational data out of a unified environment and analyze it in any given way. Like a knife to fork or a fork to fork-from-3-year-ago. Ok...I may have worn out this analogy.
Why does it matter?
The data lake pattern is the preferred architectural solution for 2020 because it provides a low cost, flexible, and scalable way to store large amounts of diverse data. All your CU data that is now sitting in dozens of siloed, vendor-specific systems is stored in a central location that you own, so it’s readily available to be categorized, processed, analyzed, enriched, and consumed by downstream analysts and operational teams. By using ‘metadata’ to tag data rather than coerce it into a predetermined warehouse format, broader types of data can be used effectively for business intelligence. When a business question arises, the data lake can be queried for relevant data in any format, and this smaller set of data is rapidly available to analyze and help answer that specific question.
From an executive perspective, the main advantage of a data lake is that it delivers strategic flexibility. Owning your data in a cloud data lake provides high levels of security, portability, and access to better tools. It doesn’t constrain future changes in business strategy because the raw data is still there. If you decide on a new BI or reporting tool, just write a job to structure the data in that format. If next year’s annual plan calls for a completely new initiative that requires answers to questions you didn’t know you needed to ask when the data lake was stood up, fine. If a new source of member data starts growing exponentially, you can handle it. The data lake approach provides a solid architectural foundation to build on for the future, even if you don’t know exactly what that future entails.
Takeaway: Strategic Flexibility, Data Flexibility, Future Proofed, Cheaper, Single Source of Truth, Better BI Integration.
How does this actually work for my CU?
The deeper purpose of deploying a data lake is to simplify decision making across the credit union. It provides the foundation for advanced analytics and the control to use the vendors you value without being locked-in. After building dozens of data lakes for Fortune 500 companies to startups, we at Blue Orange have seen a fundamental shift in the past six months that democratizes access to cutting edge data tools. In terms of cloud computing, we are “standing on the shoulders of giants,” and credit unions of any size can be the beneficiaries.
Here is a map of modern AWS data architecture for credit unions. It looks complicated, but the beauty is that these are all high-end data services that you don’t have to build. AWS has created impressive tools at every stage of the data lifecycle that can be pulled together, revolutionizing how credit unions think about and use their data.
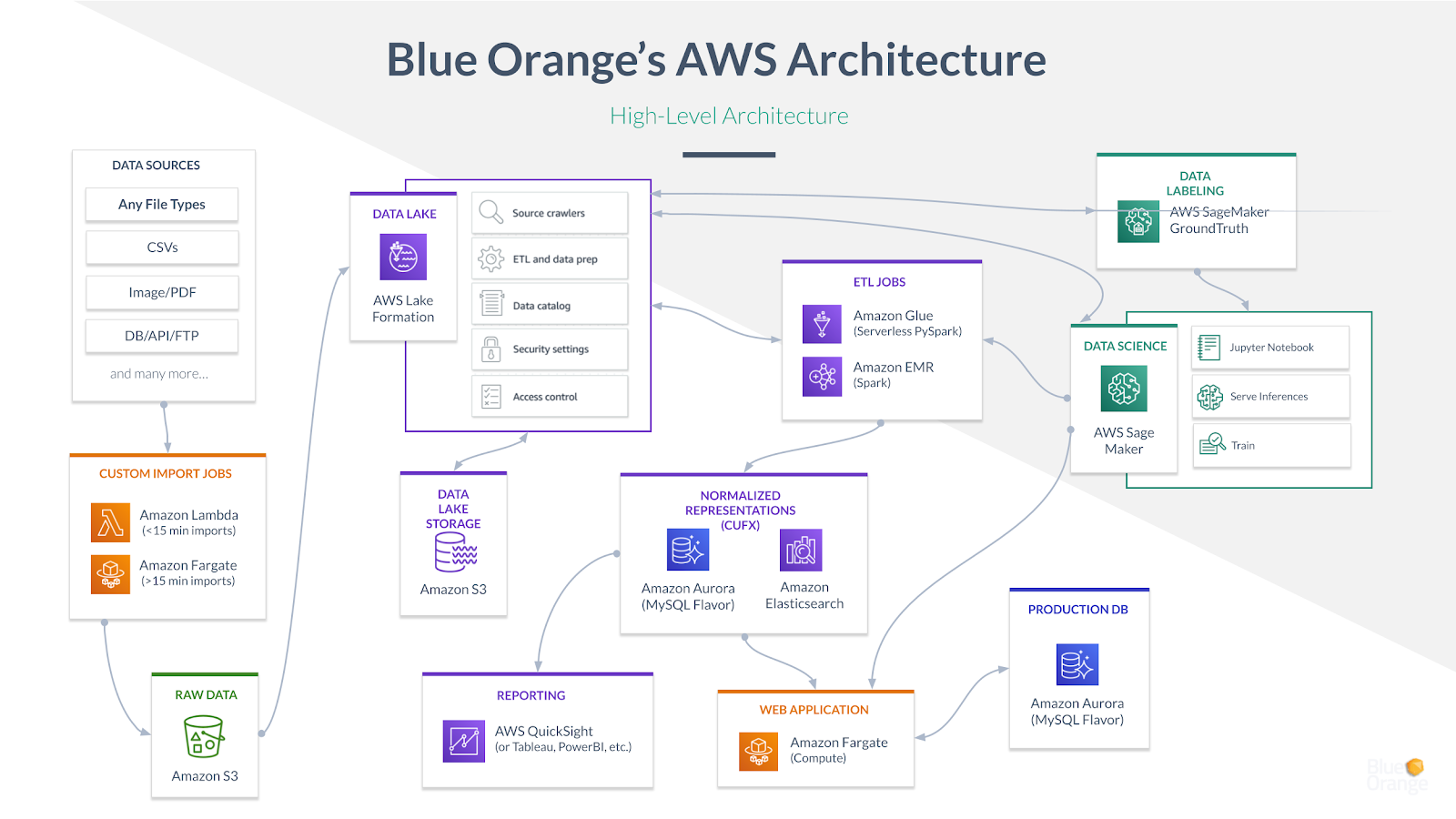
Your data is stored in its raw, persistent form in an AWS data lake built on Lake Formation. The data you need for a specific job is pulled out, transformed, normalized, and sent to an analytics engine in real-time. Let’s say you have already purchased a loan analyzing software that you love based on the CUFX schema. We write a ‘job’ that transforms a representation of your loan data into CUFX so the software can use it. But the underlying the data in the single source of truth doesn’t change. The next level is actually applying modern data science tools like EMR and SageMaker to implement machine learning models and predictive analytics. Once the data pipeline is built, you just rent the processing time.
This is not traditional IT. The time to stand up an end to end data and analytics pipeline built on AWS tooling is measured in weeks, not years.
If you want to learn more about data lakes and advanced analytics for CU, we’d love to talk. You can book me directly here.






